
はじめに
かなり前の記事ですが。
「近いうちにカスケード分類器を自作してみようと思います。」
という後書きを書いていたのを今更ながらに見つけたので、全く近いうちにできてないのですが、昔の自分の思いを受け継いでやってみました。
複数の正解画像を利用してカスケード分類器を作成しています。(1枚の画像を水増ししてカスケード分類器を作る場合と少しだけ手順が異なります)
環境を整える
作業用のフォルダ(以後「cascadefiles」とします)を好きな位置に作り、その中に次の4つのフォルダを作ります。
- pos
- vec
- neg
- cascadeout
次にカスケード分類器のトレーニング用の実行ファイルをOpenCVの本体から持ってきます。
私の場合はOpenCVの中に求めていた実行ファイルがありませんでした。
元々HomeBrewでOpenCV(4.5.0)をインストールしていたのですが、カスケード分類器のトレーニング用の実行ファイルはOpenCV(3.*.*)をインストールしないといけないようです。
ということで次のコマンドでOpenCV(3.*.*)をインストール。
brew install opencv@3
終わったらFinderから「/usr/local/Cellar/opencv@3/3.*.*/bin」に移動します。
「opencv_createsamples」と「opencv_traincascade」をコピーして最初に作った「cascadefiles」に貼り付けます。
画像を用意する
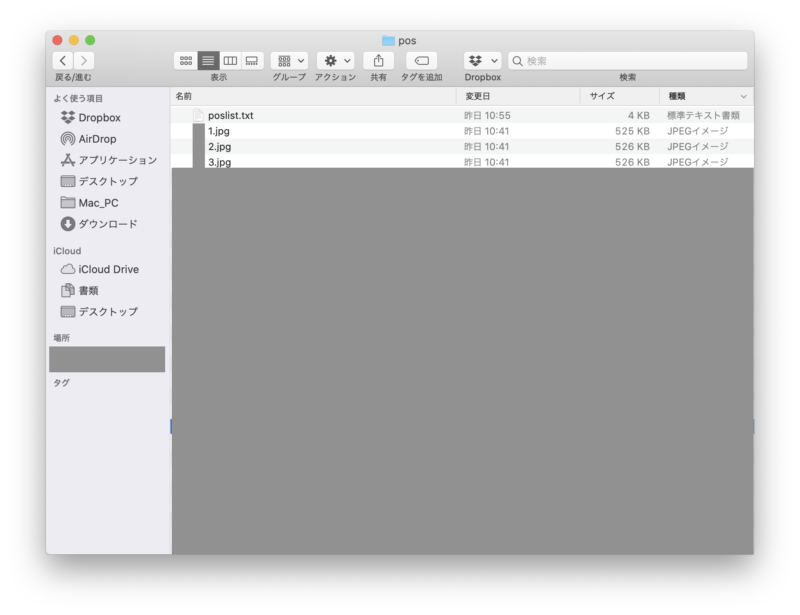
「pos」の中に正解画像、「neg」の中に不正解画像を用意します。
正解画像リストを作る
正解画像は「pos」の中に画像を用意したあと、正解画像がリスト化された次のようなテキストファイル(以後「poslist.txt」)を作成して、これも同じく「pos」の中に入れます。
1.jpg 1 508 273 103 93 2.jpg 1 500 271 116 110 3.jpg 2 518 286 106 116 506 294 113 108 … <画像ファイル> <対象の個数> <対象の位置>
対象の位置は次の順番になっています。
左上x座標 左上y座標 x軸の長さ y軸の長さ
後ろの2つが座標ではなく長さになっているので注意してください。
自分は1本の動画から1フレームずつ取り出してアノテーションをしたのですが、こちらの記事のようなアノテーションプログラムを作りました。よかったら参考にしてみてください。
opencv_createsamplesで正解画像リストをvecファイルに変換
「cascadefiles」で次のコマンドを実行します。
./opencv_createsamples -info pos/poslist.txt -vec vec/posvec.vec
注:正解画像数が1000枚より多い場合には「-num <正解画像数>」を追加して実行してください。
その他のオプションについては次の通りです。
./opencv_createsamples Usage: ./opencv_createsamples [-info <collection_file_name>] [-img <image_file_name>] [-vec <vec_file_name>] [-bg <background_file_name>] [-num <number_of_samples = 1000>] [-bgcolor <background_color = 0>] [-inv] [-randinv] [-bgthresh <background_color_threshold = 80>] [-maxidev <max_intensity_deviation = 40>] [-maxxangle <max_x_rotation_angle = 1.100000>] [-maxyangle <max_y_rotation_angle = 1.100000>] [-maxzangle <max_z_rotation_angle = 0.500000>] [-show [<scale = 4.000000>]] [-w <sample_width = 24>] [-h <sample_height = 24>] [-maxscale <max sample scale = -1.000000>] [-rngseed <rng seed = 12345>]
正解画像数が指定より少ない場合(オプションで指定しない場合1000枚)次のように出力されますが問題ありません。
pos/poslist.txt(***) : parse errorDone. Created *** samples
「vec」ファイルの中に「posvec.vec」ができていれば完了です。
不正解画像リストを作る
不正解画像の方は比較的何でも良いようなので、ネットからダウンロードするなりして「neg」に入れてください。
続いて不正解画像ファイルのパス(「cascadefiles」からみた相対パス)がリスト化された次のようなテキストファイル(以後「neglist.txt」)を「neg」の中に用意します。
neg/1.jpg neg/2.jpg … <不正解画像ファイルのパス>
次のコマンドを「cascadefiles」で実行することで簡単に用意できます。
ls neg | xargs -I {} echo neg/{} > ./neg/neglist.txt
opencv_traincascadeを実行する
最後に「opencv_traincascade」を実行してカスケード分類器を作成します。
./opencv_traincascade -data ./cascadeout/ -vec ./vec/posvec.vec -bg ./neg/neglist.txt -numPos 100 -numNeg 100
- numPos:正解画像数
- numNeg:不正解画像数
正解画像数は先ほど学習したデータ数(Created *** sample)と同等だとエラーが発生するので(正解だと判別されていない場合があるため)、学習したデータ数よりも小さな値を指定してください。
./opencv_traincascade
Usage: ./opencv_traincascade
-data <cascade_dir_name>
-vec <vec_file_name>
-bg <background_file_name>
[-numPos <number_of_positive_samples = 2000>]
[-numNeg <number_of_negative_samples = 1000>]
[-numStages <number_of_stages = 20>]
[-precalcValBufSize <precalculated_vals_buffer_size_in_Mb = 1024>]
[-precalcIdxBufSize <precalculated_idxs_buffer_size_in_Mb = 1024>]
[-baseFormatSave]
[-numThreads <max_number_of_threads = 8>]
[-acceptanceRatioBreakValue <value> = -1>]
--cascadeParams--
[-stageType <BOOST(default)>]
[-featureType <{HAAR(default), LBP, HOG}>]
[-w <sampleWidth = 24>]
[-h <sampleHeight = 24>]
--boostParams--
[-bt <{DAB, RAB, LB, GAB(default)}>]
[-minHitRate <min_hit_rate> = 0.995>]
[-maxFalseAlarmRate <max_false_alarm_rate = 0.5>]
[-weightTrimRate <weight_trim_rate = 0.95>]
[-maxDepth <max_depth_of_weak_tree = 1>]
[-maxWeakCount <max_weak_tree_count = 100>]
--haarFeatureParams--
[-mode <BASIC(default) | CORE | ALL
--lbpFeatureParams--
--HOGFeatureParams--
しばらくすると次のようなメッセージが表示されて学習が終わります。
Required leaf false alarm rate achieved. Branch training terminated.
「casacadeout」の中にカスケード分類器「cascade.xml」が生成されていたら完成です。
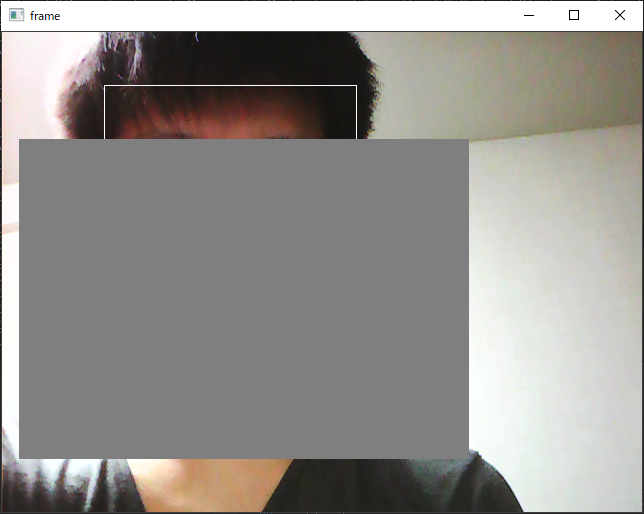
既存のカスケード分類器のように利用することができます。
最後に
思っていたよりも実行ファイルの実行の仕方が難しかったです。
かなり急ぎ足で記事を書いてしまったので、オプションなどの説明を省いてしまいました。
今回は見せられない画像(共同研究的な意味ですよ!)で作ったものの記録で書いてしまったので、いずれは結果まで見せられる画像を使ってオプションなどの説明も含めた記事を書こうかなと思います。

コメント